Word Error Rate fortæller om nøjagtigheden af et talegenkendelsessystem
Word Error Rate (WER) er en almindeligt anvendt værdi til at bestemme nøjagtigheden af talegenkendelsessystemer. WER måler, hvor mange fejl et talegenkendelsessystem laver, når tale konverteres til tekst. WER beregnes ved at sammenligne den genkendte tekst med det originale manuskript og identificere forskelle såsom tilføjede, manglende eller forkert genkendte ord.
WER beregnes som følger:
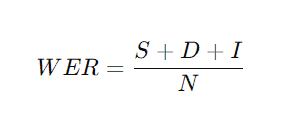
- S er forkert erstattede ord (Substitutions),
- D er manglende ord (Deletions),
- I er indsatte ord (Insertions),
- N er antallet af ord i den oprindelige tekst.
I praksis kan WER bruges til at evaluere ydeevnen af talegenkendelsessystemet i forskellige brugssituationer. Det er et nøgletal, når man udvikler og forbedrer automatiske talegenkendelsessystemer, som også bruges som en hjælp for eksempel i Spokens undertekstnings- og transskriptionsydelser.
Jo lavere WER er, jo mere nøjagtigt er talegenkendelsessystemet. Reduktion af WER er derfor et primært mål for virksomheder og forskere med fokus på at fremme talegenkendelsesteknologi.
Whisper og WER-værdier for forskellige sprog
Hos Spoken bruger vi OpenAIs talegenkendelsessystem Whisper til talegenkendelse, hvor WER-værdierne varierer afhængigt af sproget. WER er normalt lavest og dermed bedst i engelsk talegenkendelse på grund af den store mængde data, der er tilgængelig, og det faktum, at modellen er optimeret til det engelske sprog.
For engelsk kan WER være så lav som 5-6 %. I dansk, svensk og norsk talegenkendelse er WER-værdierne lidt højere, omkring 8-10 %. På finsk kan WER være endnu højere, omkring 10-12 % på grund af det finske sprogs unikke struktur og morfologi, som giver særlige udfordringer for talegenkendelsessystemer.
Denne sammenligning viser, at selvom Whisper er rigtig effektiv til mange sprog, har sprogstruktur og datatilgængelighed en betydelig indflydelse på WER.